

GPU 숫자가 곧 국가 경쟁력
페이스북과 인스타그램 등 사용자 생성 콘텐츠 미디어를 서비스하는 메타 플랫폼즈가 데이터 센터안에 들어가있는 '클러스터' 하나에 H100 카드 10만장 넘게 장착하고 Llama 4 모델을 훈련시키는 동안 국내에 있는 H100 카드를 전부 다 긁어모아도 2천장이 안된다고 한다. 메타를 비롯해 GCP, AWS, Azure 같은 글로벌 클라우드 제공자들은 한 클러스터에 10만장씩 넣고도 부족해서 프라이빗 네트워크로 여러 클러스터를 연결해서 멀티-클러스터 훈련을 가능케 하는 계획을 세우고 준비중인데 쓰루풋(throughput)이 대폭 증가한 블랙웰 세대가 2025년초 고객사들에게 전달되면 한국과 미국의 컴퓨트 인프라 격차는 다른 차원 수준으로 벌어지게 된다.

필자가 한국어 기반 파운데이션 LLM (초거대언어모델) 개발에 약간 부정적이였던 이유가 scaling law가 살아있는 한(최근 한계에 부딪혔다는 논란이 있다) 국내기업이 어떤 마법을 부려도 미국 빅테크가 엄청난 자본력을 기반으로 확보한 GPU에 데이터를 더 학습시키면 절대 성능 차이를 극복하지 못할거라는 우려 때문이었는데, 그 우려가 차곡차곡 현실화 되는중이다. 2024년 2월 기준으로 네이버의 HyperClova X가 GPT 4를 한국어 기반 LLM 벤치마크에서(KMMLU et al.,) 더 높은 성능을 보여주었다고 하지만 현재 GPT 4o와 Clova X의 한국어 문장 구사력을 비교해보면 4o가 더 자연스러운 결과물을 보여준다. 4o 모델의 토큰 가격이 훨씬 비싸지만 OpenAI가 박사급 지능을 갖추었다고 주장하는 GPT 5가 출시되고 5 mini 버전이 4o와 비슷한 성능을 낸다고 가정하면 가격적 우위도 없어지게 될 가능성이 높다.
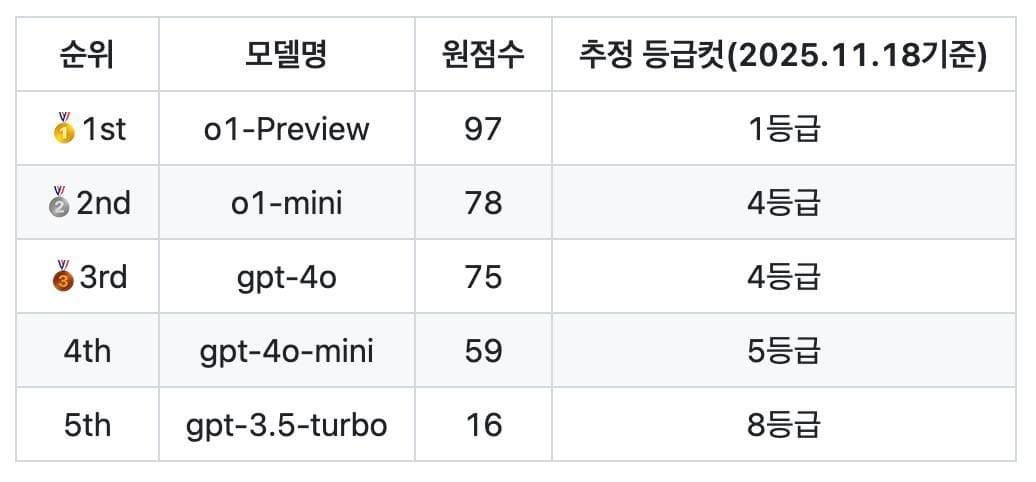
수능 1등급을 획득한 GPT o1-Preview
최초로 "chain-of-thought" 매커니즘을 적용해서 출시한 초거대언어모델인 GPT o1-Preview 모델은 2025년도 국어 수학능력시험에서 상위 4%내에 해당하는 점수를 획득했다. 경량화 된 모델인 o1-mini조차 시험자 평균을 넘어서는 4등급에 해당하는 점수를 획득했다. 상당한 수준의 문해력을 요구하는 수능시험에서 인간 대다수를 뛰어넘는 점수를 획득할 정도로 LLM은 진화를 거듭하고 있다.
업무에 대한 LLM의 본격적인 적용에 앞서 '환각' 문제를 해결해야 한다는 주장 또한 있지만 이들은 인간 또한 '환각' 문제를 갖고 있음을 애써 외면하는듯 하다. 미션 크리티컬한 어플리케이션이라면 LLM 여러개를 엮어서 서로의 추론 프로세스와 결과를 교차 검증하게 만들면 된다. 아직 AI 에이전트가 인간 수준의 업무 능력을 보여주진 않지만 이 또한 시간 문제일 것이라 생각된다.
해외 데이터를 위주로 훈련시켰기에 한국 관련 질문에 대한 답안의 오답률이 높다고 평가받는 GPT 모델에 인터넷 검색엔진을 쥐어주면 해당 문제는 해결될 확률이 높다. 공교롭게도 OpenAI는 최근 ChatGPT Search를 출시하며 검색시장에도 관심을 보이고 있다. GPT가 인터넷에서 잘못된 정보를 인용해오면 어쩌냐고? o1-Preview 모델의 성능을 기준으로 한다면 이 글을 읽고 있는 당신보다 그럴 확률이 낮다.
뛰어난 엔지니어, 한국에서 일할 이유 없어
AI 기반 검색엔진을 서비스하는 Perplexity의 CEO인 아라빈드 스리나비스(Aravind Srinivas)는 LLM을 다룰 수 있는 인재를 채용하는것의 어려움을 여러번 공개적으로 토로했다. 어느날은 구글의 경력직 직원을 어렵게 채용하기로 했는데 해당 직원의 이직 사실을 알게된 구글이 남아있는 조건으로 그가 제시한 연봉의 4배를 제시하면서 채용이 무산 되었다고 하고, 또 다른날은 메타 플랫폼즈의 수석 AI 연구원에게 이직 제안을 했지만 "H100 카드 1만장을 확보하고 나서 다시 연락달라"는 사실상의 문전박대를 당했다고 한다.
뛰어난 AI 연구원이나 엔지니어를 구하려면 연봉도 중요하지만 그들이 연구 결과를 낼 수 있는 환경이 조성되어야 한다. 세계에서 가장 뛰어난 피아니스트 중 한명이라고 알려진 조성진을 초청했는데 정작 콘서트 홀엔 장난감 피아노 하나만 덩그러니 놓여져 있다면 아무리 많은돈을 줘도 그가 수락할리 없다. Perplexity는 이미 2,000억원이 넘는 규모의 펀딩을 받았음에도 불구하고 조 단위를 투자하는 OpenAI나 미국 빅테크 기업들의 이른바 '쩐의 전쟁'에 치여 인재를 확보하는데 어려움을 겪고 있는데, 한국인이더라도 10억원 이상의 연봉 및 스톡옵션 등의 보상과 자신의 커리어를 퀀텀 점프할 수 있는 기회를 단순히 애국심만을 가지고 한국행을 선택할 엔지니어는 거의 없을것이다.
AI 자주가 중요하지 않은 이유
원천 기술력이 없다면 우리는 미국과 같은 AI 선진국에 의해 끌려 다닐 수 밖에 없다는 논리가 주요한듯 하다. 나는 이러한 골자에 동의하지 않는다. 예를 들어, 현대 경제에서 필수적인 석유에 대한 접근이 불가능한 나라는 현재 없다. 그렇다고 유가가 엄청나게 비싸지도 않으며, 오히려 셰일가스(fracking) 같은 기술 혁신으로 원유는 예전보다 접근하기 쉬워졌으며, 중동의 영향력은 저물어가고 있다.
현재는 구글, 메타, 마이크로소프트, OpenAI, Anthropic등이 수십조원을 투자하며 더 뛰어난 파운데이션 AI 모델을 개발하려 노력중이지만 이는 결국 나중에 해당 모델을 기반으로 수익화를 하기 위함이다. 수익화를 한다는 것은 결국 어떤 형식으로든 외부에 판매함을 의미하고, 우리도 접근 가능하다는 말이다. 한국에서 파운데이션 AI 모델을 개발하기 위해 수십조원치의 GPU 클러스터를 구축할 수 있는 기업은 없다. 한국에도 쌓아놓은 현금이 100조원이 넘는 삼성전자 같은 기업이 있긴 하지만 제조업 특성상 설비투자에 많은 자금이 유출되므로 그정도로 많은 GPU를 살 수 있는 자금 여력이 안되는 것이다. 더 큰 문제는 돈을 들이 내밀어도 엔비디아가 생산할 수 있는 GPU 숫자에 한계가 있기 때문에 네트워크가 없으면 구하지도 못한다는 것.
경제학의 대가 데이비드 리카도는 비교 우위론을 통해 비록 한 국가가 상대국보다 절대우위에 있더라도 상호 무역을 통해 이익을 창출할 수 있는 이유를 설명한다. 미국은 대부분의 산업에서 한국대비 절대적인 우위를 점하고 있지만, 상대적으로 제일 우위인 지식 산업에 집중하고 있고, 한국은 반도체와 중공업 등 고부가가치 제조업에 집중하다 지식 산업에도 진출하기 시작했다. 그러나 아직까지 지식산업 분야에서 전세계적인 영향력을 행사하는 기업은 없다. 구글이 절대적으로나 상대적으로나 네이버에 비해 더 나은 검색 결과를 보여주는데, 네이버가 굳이 존재할 필요는 없다는 말이다. 네이버는 그래서 검색 엔진으로서의 경쟁은 사실상 포기하고 커머스 + 미디어 콘텐츠 회사가 되었다.
모든 산업은 '추상화'를 통해 부가가치를 창출한다. 기초적인 산업위에 새로운 층을 쌓아 새로운 산업을 만들어내고, 그렇게 추상화 레이어가 겹겹이 쌓여갈수록 부가가치는 더 확대된다. 아마존의 AWS 클라우드 서비스는 사실 반도체 제품들을 기초로 소프트웨어를 얹어 '컴퓨팅'이란 자원을 추상화해서 파는것이다. AWS를 이용하는 소프트웨어 기업들은 컴퓨팅 자원 위에 자신들만의 데이터 조작 알고리즘과 UI(유저 인터페이스)를 얹어 추상화해서 재판매 하는것이다. 이렇게 우리 경제는 기초 산업위에 추상화 레이어를 수십에서 수백번 얹어 만들어진 총합이다.
석유를 직접 생산하는 국가 혹은 기업만 가치가 있는것은 아니다. 석유를 정제하는 정유, 정유된 제품들을 이용해 소재를 생산하는 화학 같은 다운스트림 산업 또한 부가가치를 창출한다. 외려, 석유만 생산하는 기업보다 정유/화학을 할 수 있는 업체의 기술 부가가치가 더 높다고 볼 수도 있다. 국산 AI 파운데이션 모델 개발에 너무 집착하지 않아도 되는 이유도 이와 같다.











토론